Procesamiento de IA local
El Procesamiento de IA local ejecuta el análisis de IA de Hedy completamente en su propio dispositivo. Sus transcripciones permanecen en el dispositivo y funciona incluso sin conexión a internet.
Está disponible en macOS (Apple Silicon), Windows (con una GPU compatible con Vulkan), iPhone 15 Pro y modelos posteriores, e iPads con chip M-series o A17 Pro. Con esta función activada, las partes de Hedy que leen su transcripción y generan texto — resúmenes, notas detalladas, indicaciones rápidas, respuestas de chat, sugerencias en sesión y retroalimentación — se ejecutan localmente en lugar de en los servidores de Hedy.
El Procesamiento de IA local es opcional y está desactivado por defecto. La mayoría de las personas no necesitan activarlo: la IA en la nube sigue siendo más rápida y un paso adelante en calidad. Está pensado para personas con requisitos de privacidad que la configuración en la nube no puede satisfacer, o que desean que Hedy funcione completamente sin conexión.
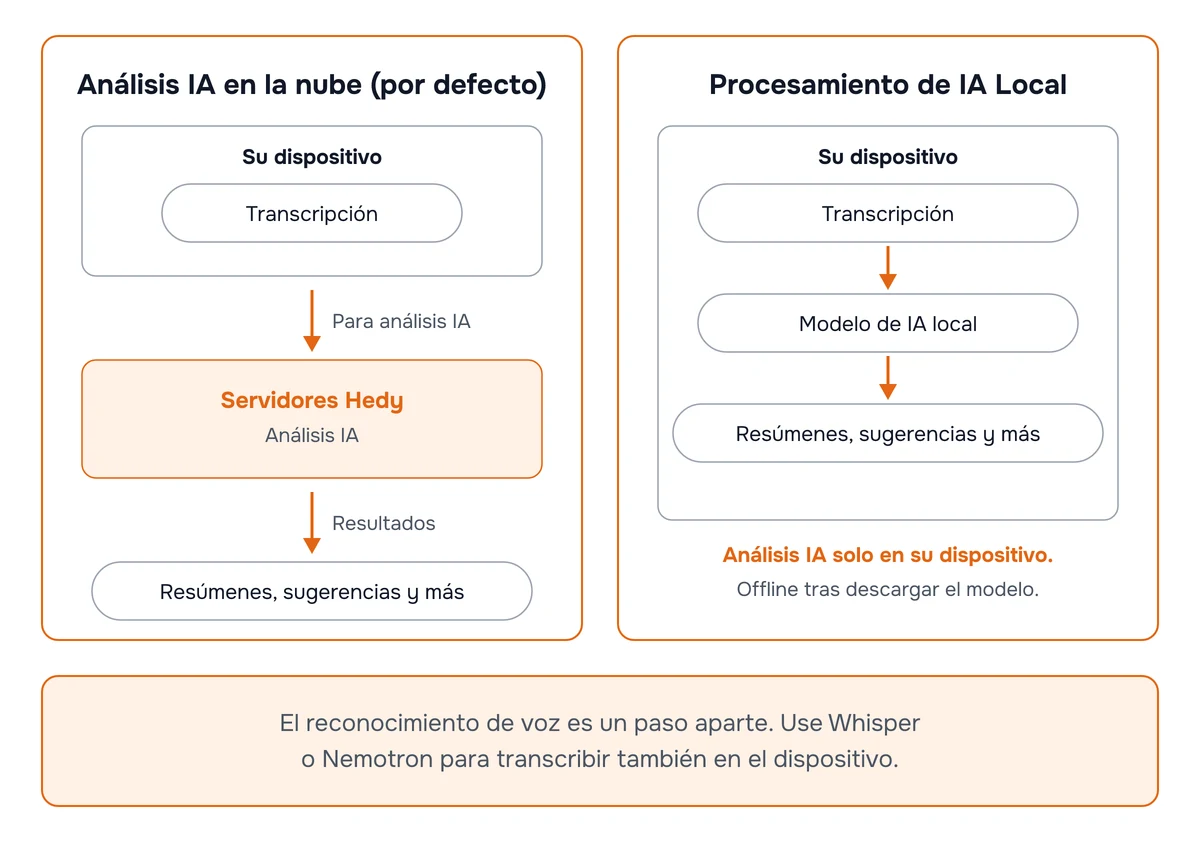
Qué hace el Procesamiento de IA local
-
Genera resúmenes de sesión, notas detalladas, indicaciones rápidas, respuestas de chat, sugerencias en sesión y retroalimentación — todo en su dispositivo.
-
Mantiene sus transcripciones en el dispositivo. Ningún dato de conversación sale de su dispositivo para el análisis de IA.
-
Funciona sin conexión una vez que el modelo está descargado.
-
Coexiste con el reconocimiento de voz basado en la nube (Deepgram, OpenAI) si los utiliza. Solo el paso de análisis de IA es local.
-
No recurre silenciosamente a la nube. Si algo falla localmente, verá un error en lugar de un reintento silencioso contra nuestros servidores — usted eligió lo local por una razón.
Requisitos
Macs con Apple Silicon (M1 o posterior). Apple Silicon comparte un único grupo de memoria entre la CPU y la GPU, por lo que el modelo debe caber en la RAM total del sistema junto con todo lo demás que esté ejecutando. Los modelos más pequeños funcionan en la mayoría de los Macs modernos. Los modelos de nivel intermedio (alrededor de 9 mil millones de parámetros) se instalan cómodamente en sistemas de 16 GB. Los modelos más grandes pueden necesitar alrededor de 25 GB de RAM para cargarse, por lo que 36 GB o más es lo recomendable para esos.
PCs con Windows con un controlador Vulkan actualizado. Lo más importante aquí es la VRAM de su GPU, no la RAM del sistema. Los modelos más grandes necesitan una tarjeta gráfica con suficiente VRAM para alojarlos. Si un modelo es ligeramente demasiado grande para su tarjeta, Hedy distribuye algunas capas a la CPU — eso funciona, pero es notablemente más lento, y el selector de modelos etiqueta esas entradas con el sufijo ”+ Slow”.
iPhone 15 Pro y posterior, además de iPads con chip M-series o A17 Pro. Restringidos a los modelos más pequeños debido a los límites de memoria en teléfonos y tabletas. Los modelos compactos manejan bien los resúmenes cortos, pero sus respuestas son notablemente más limitadas que las de un modelo más grande en un Mac.
En las plataformas nativas que aún no pueden ejecutar IA en el dispositivo — Macs Intel, Android e iPhones y iPads antiguos — la tarjeta de Local AI Processing sigue apareciendo en Settings → Speech & AI, pero en lugar de un interruptor muestra: “La IA local aún no está disponible en este dispositivo. Estamos trabajando para llevar la IA en el dispositivo a más dispositivos.” En Windows sin una GPU compatible con Vulkan, la tarjeta explica que se requiere una tarjeta gráfica compatible con controladores actualizados. (La versión web no muestra ninguna sección de IA local.)
Android y Web están en nuestra hoja de ruta, pero aún no son compatibles. La gran variedad de hardware en Android y las restricciones de ejecutar modelos dentro de un navegador hacen que sea difícil ofrecer una experiencia consistente hoy en día.
También necesitará memoria libre acorde al modelo que elija (Hedy muestra un indicador de compatibilidad en cada uno) y una descarga inicial del modelo. El tamaño del modelo oscila entre aproximadamente 2,5 GB y más de 20 GB según el modelo que elija.
Cómo activar el Procesamiento de IA local
-
Abra Hedy y vaya a Settings → Speech & AI.
-
Desplácese hasta la sección Local AI Processing y actívela.
-
Elija un modelo de la lista que se adapte a la memoria de su dispositivo. Busque la etiqueta “Great fit”.
-
Espere a que el modelo termine de descargarse. Verá el progreso y el tamaño en GB.
-
Una vez descargado, el Procesamiento de IA local estará activo. Inicie una sesión como de costumbre.
El Procesamiento de IA local se configura por dispositivo. Para usarlo en su Mac y en su iPhone, actívelo y descargue un modelo en cada uno — la configuración y los archivos del modelo no se transfieren entre dispositivos.
Elegir un modelo
El selector de modelos muestra varios modelos con una calificación de estrellas según su tamaño:
-
★ (1 estrella) — Adecuado para resúmenes básicos de reuniones y notas cortas. Puede tener dificultades con reuniones largas o preguntas de seguimiento complejas. Rango de parámetros: 2–5 mil millones.
-
★★ (2 estrellas) — Sólido en todo. Gestiona bien los resúmenes de reuniones, notas detalladas y chat. Las conversaciones muy largas o muy técnicas pueden ser más difíciles. Rango de parámetros: 8–10 mil millones.
-
★★★ (3 estrellas) — Cercano a nuestra IA en la nube en calidad. Gestiona reuniones largas, temas amplios, notas complejas y preguntas de seguimiento intrincadas de forma fiable. Rango de parámetros: 15+ mil millones.
Hedy verifica automáticamente la memoria disponible en su dispositivo y clasifica cada modelo:
-
Great fit — recomendado. Amplio margen disponible.
-
Tight fit — funcionará, pero puede ser lento o inestable si ejecuta muchas otras aplicaciones.
-
Won’t fit — no elija este.
En Windows, los modelos que necesitan distribuir capas a la CPU muestran el sufijo ”+ Slow” para que sepa lo que está eligiendo.
Si no está seguro, comience con el modelo más grande que muestre “Great fit” para su dispositivo. Puede cambiarlo más adelante. Los modelos se guardan en el almacenamiento de la aplicación tras la descarga, y puede eliminar uno en cualquier momento desde la misma pantalla para recuperar espacio en disco.
Cambiar entre IA local y en la nube
-
Desactive el Procesamiento de IA local para volver al análisis basado en la nube.
-
No perderá ninguna sesión al cambiar. Las sesiones existentes conservan sus notas y resúmenes actuales.
Privacidad
Cuando el Procesamiento de IA local está activado, sus transcripciones y el contenido generado por IA (resúmenes, notas, respuestas de chat, sugerencias, retroalimentación) nunca salen de su dispositivo para el análisis de IA. Las descargas de modelos provienen de los servidores de Hedy, pero no contienen ninguno de sus datos.
Lo que fluye a nuestros servidores depende de si Cloud Sync también está activado:
-
IA local activada, Cloud Sync desactivado. Nada sobre sus reuniones sale del dispositivo. Las grabaciones de audio, transcripciones, resúmenes, notas, respuestas de chat y sugerencias permanecen en el dispositivo.
-
IA local activada, Cloud Sync activado. El procesamiento de IA sigue ocurriendo completamente en su dispositivo — su transcripción y el texto generado nunca se envían para su procesamiento. Los datos de su sesión siguen sincronizándose (cifrados) con los servidores de Hedy para que pueda acceder a ellos entre dispositivos, de la misma manera que Cloud Sync siempre ha funcionado.
En ambos casos, la información de la cuenta, los datos de uso y los informes de errores continúan fluyendo a través de nuestros servidores para que la aplicación pueda funcionar. Ninguno de estos contiene el contenido de las transcripciones ni el resultado generado por IA.
Para la configuración más estricta, combine el Procesamiento de IA local con Cloud Sync desactivado — sus conversaciones entonces solo existirán en el dispositivo que las capturó.
El reconocimiento de voz es un paso separado. Si utiliza un proveedor en la nube como Deepgram o OpenAI para la transcripción, su audio seguirá fluyendo a través de ese proveedor. Para mantener ambos pasos en local, combine el Procesamiento de IA local con reconocimiento de voz en el dispositivo como Whisper o Nemotron. Consulte nuestra guía Proveedores de reconocimiento de voz.
Consejos prácticos
-
Desactive Automatic Suggestions para sesiones locales largas. Mantienen el modelo local muy ocupado durante toda la sesión y pueden ralentizar todo lo demás en su máquina (y generar mucho calor). Hedy le avisa sobre esto cuando activa el Procesamiento de IA local por primera vez.
-
Conecte su portátil o teléfono a la corriente para sesiones largas. La inferencia continua en el dispositivo consume la batería más rápido de lo que esperaría.
-
Elija un modelo que se ajuste cómodamente a su hardware (RAM en Mac e iOS, VRAM en Windows). Un “Tight fit” funciona, pero deja menos margen para todo lo demás que esté haciendo.
Solución de problemas
Las respuestas son más lentas que en la nube
Es lo esperado. Un resumen que parece instantáneo en la nube puede tardar entre 30 segundos y varios minutos en local, dependiendo de su hardware y del modelo que elija. Los modelos más grandes son más lentos pero más capaces.
El modelo no se descarga
-
Verifique su conexión a internet y el espacio disponible en disco.
-
Reinicie Hedy e inténtelo de nuevo.
-
Algunos modelos tienen varios GB. Las descargas pueden tardar un tiempo en conexiones lentas.
-
En Windows, el software antivirus puede interrumpir descargas de gran tamaño o poner en cuarentena los archivos del modelo. Consulte Windows Antivirus Blocking Hedy Download or Installation si esto ocurre.
Las respuestas son muy lentas o la aplicación no responde
-
Verifique los requisitos de RAM/VRAM del modelo frente a lo que está libre en su dispositivo. Un modelo “Tight fit” compitiendo con otras aplicaciones puede ejecutarse lentamente.
-
Cierre aplicaciones que consuman mucha memoria y no esté utilizando (pestañas de navegador adicionales, apps en segundo plano).
-
Pruebe con un modelo más pequeño.
-
En Windows, confirme que el controlador de su GPU esté actualizado. Consulte Fix Slow Transcription on Windows (GPU Settings) para orientación sobre controladores; los mismos consejos aplican a la IA local.
“Local AI model not ready” al iniciar una sesión, importar o fusionar
Esto significa que Local AI Processing está seleccionado pero aún no hay ningún modelo descargado, por lo que Hedy no tiene motor para generar resultados de IA. Abra Settings → Speech & AI para descargar un modelo, o vuelva a la IA en la nube para continuar de inmediato. Hedy ahora muestra esto antes de que comience la sesión en lugar de fallar silenciosamente a mitad del proceso.
“Local AI lost access to your model”
Hedy ya no puede acceder a un modelo que usted agregó previamente — normalmente porque el archivo se movió o eliminó fuera de la aplicación. Abra Settings → Speech & AI, elimine ese modelo y agréguelo de nuevo.
Las funciones de IA indican “not available”
-
Confirme que el modelo haya terminado de descargarse (verifique la sección Local AI Processing en la configuración). Un modelo cuya descarga se interrumpió ya no aparece como “Downloaded”; vuelva a descargarlo si es así.
-
Desactive y vuelva a activar el Procesamiento de IA local.
Comentarios
Ejecutar IA completamente en su dispositivo es algo nuevo y aún está en una etapa temprana. Los modelos locales son más pequeños que los modelos en la nube, por lo que las respuestas pueden ser menos precisas o detalladas, y en algunos sistemas puede encontrar inestabilidad o arranques lentos. Estas limitaciones irán reduciéndose a medida que la IA local madure, y seguiremos ampliando el soporte a más plataformas conforme la tecnología lo permita.
Envíe un correo a support@hedy.ai con cualquier comentario o problema.
Relacionado: Control de privacidad del análisis de IA en la nube, Proveedores de reconocimiento de voz.

